Scraping TripAdvisor reviews using R

I recently wrote a brief tutorial on using Python to scrape Tripadvisor reviews. I'm a big advocate of using RStudio for marketing analytics (I'll write up a post explaining why soon), so I thought I'd revisit this exercise using R.
We'll use Selenium again, this time the RSelenium package. Selenium is a tool that lets you control your desktop browser programmatically. Tripadvisor requires a "read more" button to be clicked to reveal the entire review, and Selenium is a good tool to easily get this done.
Create a project
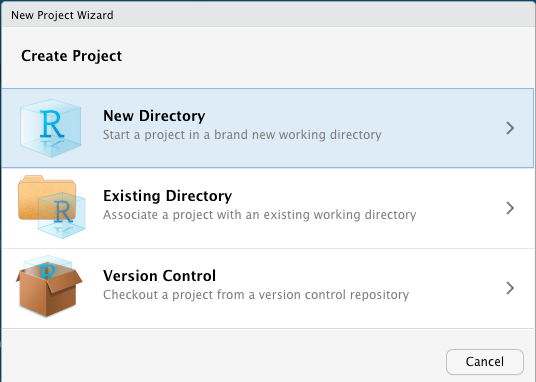
We'll assume you're using RStudio for this experiment. Create a new project by clicking File > New Project.
Select new project
And again
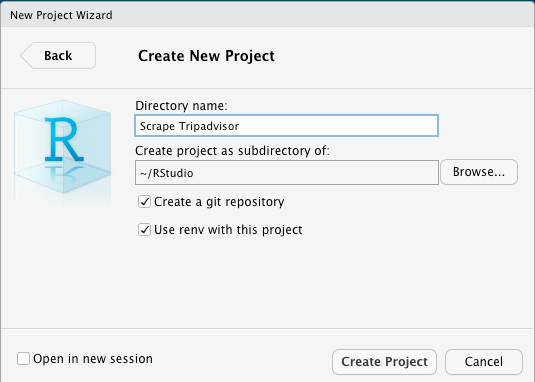
Name your project. It's a good idea to click the "renv" box here, because it'll create an environment just for this project. In this way when you install packages, they won't conflict with other packages. You should also create a git repo so you can track changes.
Install the required packages
In the RStudio console, install the packages we'll use with this exercise:
Tidyverse is a set of packages that make data wrangling and manipulation easier. You should probably install it by default in all your exercises
install.packages("tidyverse")
Install Selenium with:
install.packages("RSelenium")
We'll use the html parsing tool in R "rvest" (as in "harvest")
install.packages("rvest")
We'll also use a function from the sys library
install.packages("sys")
Build the program
Create an R Notebook in R Studio. The notebook lets you build a program using "chunks" of code. In the first chunk, we'll load our libraries
library("RSelenium")
library("rvest")
library("tidyverse")
library("sys")
Define the variables
We'll just do a very basic one page scrape for this exercise, getting into multiple pages in another post. So for now, let's define the url as our only variable.
url <- "https://www.tripadvisor.com/Hotel_Review-g60982-d209422-Reviews-Hilton_Waikiki_Beach-Honolulu_Oahu_Hawaii.html"
Fire up Selenium
We'll navigate to the URL with Selenium. What the next bit of code will do is launch Firefox and navigate to the URL we defined above:
rD <- rsDriver(browser="firefox", port=45354L, verbose=F)
remDr <- rD[["client"]]
remDr$navigate(url)
Open all the reviews
The reviews in Tripadvisor are all truncated. We need to click the "read more" link to get them all to open up. Let's do that now.
# First wait for the DOM to load by pausing for a couple seconds.
Sys.sleep(2)
# Now click all the elements with class "expand review"
remDr$findElements("xpath", ".//div[contains(@data-test-target, 'expand-review')]")[[1]]$clickElement()
Scrape the HTML and make it available for rvest
Now we'll scrape the html on the page and place it in a variable cleverly called "html"
html <- remDr$getPageSource()[[1]]
We'll use the readhtml function of rvest to wrangle the data into a form R can use. We're done with Selenium now.
html <- read_html(html)
Parse the HTML and put the required data into dataframes
This section of code grabs the data we're looking for and places it in a dataframe (called a "tibble" in R). If you're not familiar with the %>% symbol, it's a pipe. You can read it as "and then."
For example the first section grabs the reviews
reviews <- html %>% # Name a variable reviews and take a look at the html
html_elements(".cPQsENeY") %>% # In particular, look at the class named .cPQsENeY
html_text() %>% # Grab the text contained with this class
as_tibble(reviews) # And save it as a tibble to reviews.
Repeat this for the other two pieces of data
dates <- html %>%
html_elements("._34Xs-BQm") %>%
html_text() %>%
str_remove_all("Date of stay: ") %>% # Remove unwanted strings
as_tibble(dates)
score <- parsedPage %>%
html_elements(".nf9vGX55") %>%
html_children() %>% # Look at the child of the named class
html_attr("class") %>% # Grab the name of the class of the child
str_remove_all("ui_bubble_rating bubble_") %>% # Remove unwanted strings
as_tibble(dates)
Combine the tibbles into one dataframe
Combine the data we've retrieved.
combined <- bind_cols(dates, score, reviews)
Write the data to a csv
Now take the combined data and write it to a csv file.
write_csv(
combined,
"reviews.csv",
na = "NA",
append = TRUE,
col_names = FALSE,
quote_escape = "double",
eol = "\n",
)
Loop through the pages
That's it! The next step to expand on this exercise is to define a number of pages and loop through each one, doing the same functions for each loop. To do this we'll need to define the number of pages to scrape, and then have Selenium click the "next page" button at the beginning of each loop.