Boolean indexing using Pandas

Introduction
Here’s a quick reference for exploring data using Boolean indexing in Pandas. Remember that a boolean operation returns only True or False, and can only be performed against a series.
Using booleans in data is usually a two-step process: the first step is to evaluate the series and identify which cell is true and which is false relative to the given boolean. The second step is to filter the series based on the boolean result.
Operators
|Operator | Description |
| ----------- | ----------- |
|== a | True if a is True, else False|
|~a| True if a is False else False (Not a) |
|a > b| True if a is greater than b else False|
|a < b| True if a is less than b else False|
|a & b | True if both a and b are True, else False|
|a | b| True if either a or b is True. False if both are False|
Filtering a dataframe
Consider the following simple dataframe, which samples four people associated with the number of times the person has seen Star Wars:
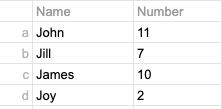
Let's establish a boolean to evaluate which people have see the film fewer than 10 times.
`evaluation = df['number'] < 10
What this does is evaluate every entry in the column 'number', compare it with the boolean, and place the result in the series "evaluation." Now we have evaluation, a series that evaluates the truthiness of the boolean.
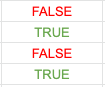
The second step is to use this true/false evaluation as a filter, creating a new series populated by values that are true.
`deprived_persons = df['evaluation']

Now we have a new series called deprivedpersons that contains two rows. If we like, we can filter just one column:
`deprived_persons = df['evaluation', "name"]
Selecting specific data
Select all rows whose country value is either Brazil or Venezuela
`brazil_venezuela = f500[(f500["country"] == "Brazil") | (f500["country"] == "Venezuela")]
Select the first five companies in the Technology sector for which the country is not the Germany
`outside_Germany = df[ ~(df["country"] == "Germany") & (df["sector"] == "Technology")].head(5)